jonathan@researchcomputingteams.org
Hi!
I wanted to give you an update on the co-op hiring mini-fiasco from last week.
Even with the chaos, we still managed to get 3 of our top 4 candidates, because we still have a great team, a sensible set of interview questions, we contacted candidates (just!) before the interview, and followed up afterwards.
None of this excuses the chaos, additional stress on the interviewers, or missed opportunities for continuous learning from the interviews and hires. But maybe there are two additional morals we can take from the end to this story:
Plus a very trenchant comment on the situation sent in by a long-time reader:
Sometimes the manager is the worker the manager needs to manage the closest. ;-)
This Dursi fellow is definitely one of the team members I have to keep a pretty close eye on.
Anyway, on to the roundup:
My Team Is Going In Circles. Help! - Lara Hogan Don’t Assume Consensus In The Absence of Objection - Candost Dagdeviren
A couple of articles about debugging team issues.
In the first Hogan addresses the issue of stuff being done, but without real forward progress. In her estimation, the biggest issues in that situation is either lack of clarity of either the underlying goals or roles and who’s in charge of what. Being clear about - and communicating relentlessly - the most important outcome can help with the first, and identifying roles and decision making processes can help with the second. Further, she points out that this is a teaching/coaching opportunity, so that the situation doesn’t repeat.
In the second, perhaps related, article, Dagdeviren reminds us that there can be disagreement over the goals or the roles without it being voiced, and especially not to you, as an objection. In meetings and in one-on-ones it can take active questioning on your part - and on the part of other team members - to uncover doubts, questions, or disagreements.
What needs to change? That’s easy. How and when is the hard part. - Nikhyl Singhal
We’ve seen in the last 22 months that things can change very quickly when everyone agrees they need to change. Singhal talks about the preconditions for enacting change, such as when many of us went to remote work:
It’s necessary, but not enough that there’s widespread agreement on the problem that needs solving; it then needs to be understood to be a priority to solve. Only then can you successfully start making the changes - by starting with some quick wins, and gaining the resources (people, time, and the trust of people who will be affected) to make the big change.
The Integrator Burden - John Cutler
We’ve talked about the “glue work” involved in being a manager in the newsletter below, but that’s kind of a nebulous term. Cutler introduces a different term and role description, that of “integrator”, which may convey the value of the work more clearly.
As managers and leads, we’re often charged with integrating the work of others - or making sure that it can be integrated - as well as making sure that our team overall, other teams, and stakeholders like researcher groups are all working together smoothly. This is hard work!
I’ve never liked the jargony term “aligning”, and “glue work” is pretty unclear - thinking of some of our responsibilities as involving integration of work and teams is maybe a better way of communicating this kind of work.
That Burning Feeling When You’re Right - Roy Rapoport
Rapoport reminds us that being right is nothing. Seeing the correct path to take is table stakes. If you can’t convince others to join you on that path, nothing will get accomplished.
5 Reasons Not to Quit Your Job (Yet) - Amii Barnard-Bahn, HBR
There are a lot of opportunities out there right now - certainly in industry, but also in academia. (There are academic research computing jobs on the job board that have been open for six months). It’s worth thinking about if you have what you need in your current job. Barnard-Bahn suggests reasons to not look elsewhere:
If two or more of those don’t apply to you, well, then…
AWS, Arm and A-HUG team up to host a wildly successful HPC Cloud hackathon (with pizza) - Oliver Perks, Arm
We’ve talked about the Arm/AWS HPC hackathon before (e.g. #84) but all there really was to refer you to was a twitter thread - which is a shame, because by all accounts it was extremely successful. In this article, Perks writes up the dual objectives they chose: get a bunch of HPC applications working on Arm, with a baseline performance measurement, but also have a reproducible event (the infrastructure part is written up here).
Then they cover the prep work - curating a list of 100 applications, assembling a list of 53 mentors (!) as well as the team, and assembling a lecture series to take place during the week. They also chose two pieces of software to make things reproducible and common across teams- Spack for documenting/implementing the build process and ReFrame as a testing and performance testing framework. They also provided each team 2 geolocated AWS pcluster setups (1 Arm, 1 Intel), with various compiler suites and performance/debugging tools.
Everyone used a common GitHub repo, with various submissions coming in as PRs. Teams were in 12 different time zones, and bias to Europe and America in volunteer mentors meant that the Asian & Australian teams were comparatively under-mentored. There were two daily synchronous sync-up meetings for catch-up, talks, and Q&A, and communications via Slack. They also monitored the ReFrame outputs using Greylog (see figure below) which also provided everyone a dashboard as to what was going on.
Perks highlights a few results in - including results that weren’t 100% successful by the end of the event! - but show that there was something that could be built on, which advances the first objective of the hackathon.
Obviously, the sorts of community hackathons we organize for our communities and tools won’t be able to be as well-resourced as this, but it’s really nice to see written up the objective, how they planned the event to advance that objective, and how much preparatory work they put in to make sure everything went smoothly.
My Logging Best Practices - Thomas Uhrig
Uhrig gives his best practices for writing logging code:
A couple articles about new (to me) tools for sharing or just looking at data this week, and a couple new (to me) courses for teaching data science:
ROAPI: An API Server for Static Datasets - Mark Litwitschik
It’s never been easier to stand up an API on top of a dataset - there’s datasette which puts data up on top of an sqlite database, or PostgREST which implements an entire CRUD API (with authentication and authorization!) on top of a PostgreSQL schema.
Litwitschik walks us through getting started with Qingping Hou’s ROAPI. ROAPI doesn’t require a database; it’s based on the Rust implementation of Apache Arrow, which means it reads directly from CSVs, JSON, or Parquet files from the local file system, http, S3, etc - or even directly from Google Sheets. It exposes read-only REST, GraphQL, or SQL interfaces; only the SQL interface supports joining between tables.
An Introduction to VisiData - Jeremy Singer-Vine
This is a user-contributed tutorial to a tool I had never heard of before, VisiData - a ~4 year old terminal tool to inspect, view summary statistics of, transform, or even make simple plots of data files. Visidata will read CSVs, HTML tables, Excel sheets, numpy save files, HDF5, JSON, sqlite data, and more, and seems like a really useful tool for initial data exploration in the terminal.
Data Science for Beginners - A Curriculum - Jasmine Greenaway, Dmitry Soshnikov, Nitya Narasimhan, Jalen McGee, Jen Looper, Maud Levy, Tiffany Souterre, Christopher Harrison Data 8: The Foundations of Data Science - UC Berkeley
Two good, well-thought out, data science courses with strong hands-on components for those starting out. They’d be solid starting points for any training curriculum.
The first is very hands on, from the Azure cloud advocacy team; there are links out to resources on Microsoft learn for hands on with particular tools, but the core of the curriculum doesn’t assume anything except Python installed and some very basic Python familiarity. The last section which includes things like deploying models assume Azure tooling.
The second is the evolving UC Berkeley Data 8 course, which is longer, more lecture based, and more rigorous about fundamentals, as one might expect from a University course - there are materials there for 17 (and a half - the evolving Fall 2021 version) instances of the course, with well-tested slides, demos, and lecture videos.
Running GROMACS on GPU instances: single-node price-performance - Part 1, Part 2, Part 3 - Carsten Kutzner and Austin Cherian, AWS HPC Blog
This is a series of articles by Kutzner (Max Planck Institute for Biophysical Chemistry) and Cherian (AWS) benchmarking standard GROMACS benchmarks on single nodes and cross-nodes across various node types. The benchmarks were run on AWS, but the articles - particularly parts 1 and 2 - are useful even if you’ll only ever run GROMACS on on-prem systems.
Part 1 is a very succinct explanation of the current work distribution on GROMACS between GPUs and CPUs, and the limits of what can and can’t be pushed off to multiple GPUs. Part 2 looks at performance and price-performance of various single-node configurations with a variety Intel CPU and NVIDIA GPU configurations, which will be of interest for those building on-prem systems where GROMACS is a major use case (spoiler: best single-node performance was on the g4dn.metal instances, with 8 T4 Tensor core GPUs and 48 cascade lake cores; best price-performance was the same class but smaller, g4dn.xlarge, with 1 T4 tensor core GPU and 2 cores - this beat out even the baseline c5 all-CPU no-GPU instance). On the other hand, they were starting to see efficiency drops for larger problems for the high-GPU instances - GROMACS isn’t quite able to take full advantage of the GPUs (given the CPUs available) in this case.
Part 3 is now more AWS specific, since the network becomes involved. For the medium and large (2M and 12M atoms) problems, and using the EFA-network-enabled instances, the GPU-heavy instances like g4dn.metal still have pretty good performance to 6 or 8 nodes, and generally handily beat out the cpu-only instances out to 18 nodes or so, but price-to-performance generally lose out to the CPU instances past 12 nodes or so. On the other hand it seems pretty sensitive to the problem size (and, presumably, the nature of the problem).
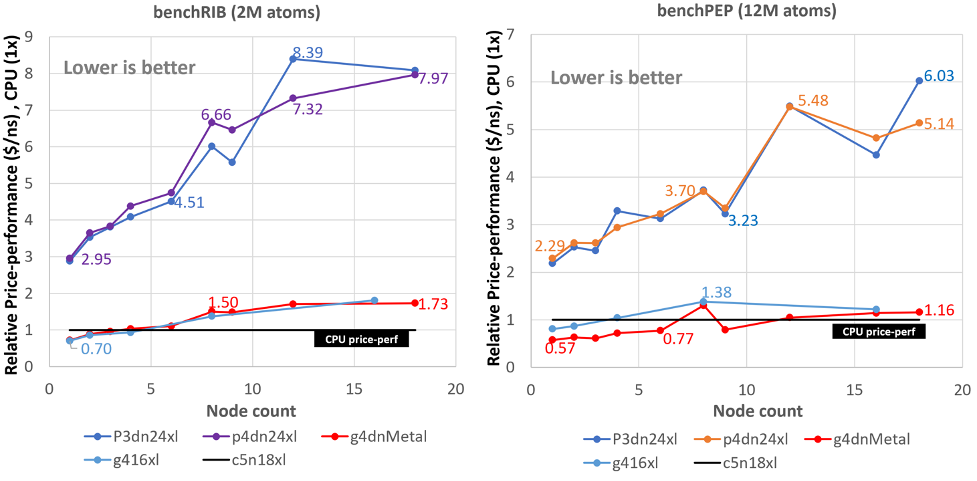
These sorts of benchmark runs are extremely time-consuming (especially this level of detail, describing why there’s a weird feature in the scaling graphs at 8 nodes) and aren’t very publishable, but are useful to the whole community, so it’s nice to see them written up regardless of who does it.
Principles and Practice of Parallel Programming (PPoPP) 2022 - 12-15 Feb, Seoul, Workshop & Tutorial Proposals due 29 Oct
Call for half- or full-day tutorials or workshops on topics relevant to the conference: “all aspects of parallel programming, including theoretical foundations, techniques, languages, compilers, runtime systems, tools, and practical experience.”
International Workshop on Arm-based HPC: Practice and Experience (IWAHPCE-2022) - 12-14 Jan, Papers due 31 Oct
Part of HPC Asia in Japan. From the call, they are particularly looking for papers on the following topics:
Platform for Advanced Scientific Computing (PASC22) - 27-29 June, Basel Switzerland, Minisymposia EOIs due Nov 12, Papers due 12 Dec, Posters due Jan 19
Sessions are arranged around 8 themes, with topics in each ranging from extremely scalable methods to tooling to applications:
Seminar Series on Tensor Computation, CS Dept, University of Oxford - 15 Oct - 3 Dec
Series of weekly seminars covering many aspects of programming languages, runtimes, and more for computing on multidimensional arrays.
Arm HPC Users Group Hackathon - SC21 - 11-12 Nov, free.
A follow up event to the previous AWS/Arm hackathon described above, this event is less AWS specific, and includes the possibility of using systems at Stony Brook University, University of Bristol, or Oracle cloud, as well as AWS.
An argument that teaching hypothesis testing should begin with the introduction of the false discovery rate, not p-values.
A free online undergrad textbook, Introduction to Probability for Data Science.
Web animations, images, videos, and interactive tomfoolery made entirely out of HTML checkboxes.
You can even play DOOM rendered entirely with checkboxes.
Quick tutorial to httpie, a much easier-to-use alternative to curl for REST API calls.
Commercial cloud companies continue to trying hard to get into the notoriously penny-pinching research computing and data market - AWS with a page of 10 minute tutorials specifically for research.
What happens on linux when you rmdir your working directory out from under yourself, and consequences for parallel tree traversal and very long paths.
An argument for “no surprises” as the measure of software quality.
Had trouble visualizing spherical harmonics when slogging through E&M problems in Jackson? Nice example of explanation with animations of circular harmonics, which are 2D spherical harmonics and thus just Fourier series on the unit circle.
Building a “fast” 6502 with an FPGA.
Trapezoid-rule numerical integration written in SQL, as you do.
If your workflow involves a lot of rebases - or rearragements of entire subtrees - and they often don’t require handling merge conflicts, you may be interested in git move.
If you’ve found yourself thinking GitHub basically became an entirely new and more interesting company starting ~2018, you’re not wrong. Here’s an interesting twitter thread about leading its turnaround.
50 years ago this week, the first commercial video arcade game.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.